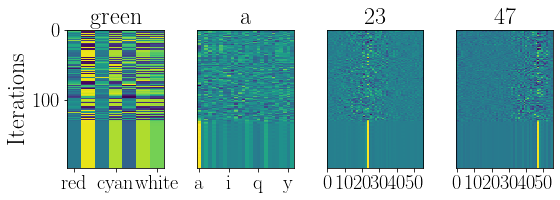
from pylab import *
import scipy
import time
import matplotlib.font_manager
import res_utils as ru
from scipy.ndimage import shift
from PIL import ImageFont
from skimage.transform import resize
%matplotlib inline
plt.rcParams.update({'font.size': 14})
plt.rcParams.update({'text.usetex': True})
plt.rcParams.update({'font.family': 'serif'})
plt.rcParams.update({'font.family': 'serif', 'font.serif':['Computer Modern']})
np.set_printoptions(precision=3)
# You might want to see the fonts on your system and choose a different font
#matplotlib.font_manager.findSystemFonts(fontpaths=None, fontext='ttf')
def norm_range(v):
return (v-v.min())/(v.max()-v.min())
Factorization of shape, color and location#
In this notebook, we are going to set up a simple scene analysis problem that can be solved with the resonator network. This example generates a scene by combining several factors to create an object: the object is a conjunction of shape, color and location. The shapes of the objects are given by fixed templates (letters chosen from a font). The goal will be to use VSA principles and resonator networks to infer the factors of each object from the scene.
First, lets get some letters for the scene.
# This will determine the size of the scene
patch_size=[56, 56]
font = ImageFont.truetype('Georgia', size=18)
letters = 'abcdefghijklmnopqrstuvwxyz'
font_ims = []
fim_size = (patch_size[0],patch_size[1],3)
for l in letters:
font_obj = font.getmask(l)
imtext = np.array(font_obj)
imsize = font_obj.size #font.getsize(l)
imtext = np.tile(imtext.reshape((imsize[1], imsize[0], 1)), (1,1,3))
imtext = imtext[:patch_size[0], :patch_size[1], :]
imsize = imtext.shape
fim = np.zeros(fim_size)
fimr = int(np.floor((fim_size[0] - imsize[0])/2))
fimc = int(np.floor((fim_size[1] - imsize[1])/2))
fim[fimr:(fimr+imsize[0]), fimc:(fimc+imsize[1]), :] = imtext/255
font_ims.append(fim)
imshow(font_ims[11], interpolation='none')
<matplotlib.image.AxesImage at 0x16c3b2070>
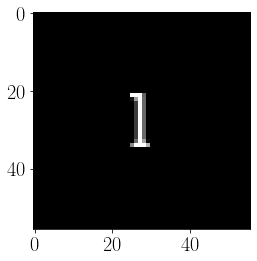
Encoding locations with the exponentiation trick#
The first step of the scene analysis is to encode the scene into a high-dimensional VSA vector. This VSA encoding has some special properties. The first is that the encoding vectors for the pixels are designed in a special way such that the properties of translation are available as a simple operation.
Translating the scene in this fashion is possible because the pixels are encoded using the “exponentiation trick”, where each pixel position is encoded by a single base vector raised to a power. For example, the vertical position 10 is encoded as \(V^{10}\). Similarly, the horizontal position has base vector and is also exponentiated by the pixel location. The 2-D location is then indexed as the binding between the vector encodings, e.g. the position 10, 20 is given by \(V^{10} \odot H^{20}\).
N = int(3e4)
# These are special base vectors for position that loop
Vt = ru.cvecl(N, font_ims[0].shape[0])
Ht = ru.cvecl(N, font_ims[0].shape[1])
# This is a set of 3 independently random complex phasor vectors for color
Cv = ru.crvec(N, 3)
def encode_pix(im, Vt, Ht):
N = Vt.shape[0]
image_vec = 0.0 * ru.cvecl(N, 1)
for m in range(im.shape[0]):
for n in range(im.shape[1]):
P_vec = (Vt ** m) * (Ht ** n)
image_vec += P_vec * im[m, n]
return image_vec
def encode_pix_rgb(im, Vt, Ht, Cv):
N = Vt.shape[0]
image_vec = 0.0 * ru.cvecl(N, 1)
for m in range(im.shape[0]):
for n in range(im.shape[1]):
for c in range(im.shape[2]):
P_vec = Cv[c] * (Vt ** m) * (Ht ** n)
image_vec += P_vec * im[m, n, c]
return image_vec
def decode_pix(image_vec, Vt, Ht):
N = Vt.shape[0]
im_r = np.zeros(patch_size)
for m in range(im_r.shape[0]):
for n in range(im_r.shape[1]):
P_vec = (Vt ** m) * (Ht ** n)
im_r[m, n] = np.real(np.dot(np.conj(P_vec), image_vec)/N)
return im_r
def decode_pix_rgb(image_vec, Vt, Ht, Cv):
N = Vt.shape[0]
im_r = np.zeros(fim_size)
for m in range(im_r.shape[0]):
for n in range(im_r.shape[1]):
for c in range(im_r.shape[2]):
P_vec = Cv[c] * (Vt ** m) * (Ht ** n)
im_r[m, n, c] = np.real(np.dot(np.conj(P_vec), image_vec)/N)
return np.clip(im_r, 0, 1)
l_idx=0
f_vec = encode_pix_rgb(font_ims[l_idx], Vt, Ht, Cv)
# translate the image
f_vec_tr = f_vec * (Vt**5) * (Ht**30)
f_im = decode_pix_rgb(f_vec_tr, Vt, Ht, Cv)
subplot(121)
imshow(font_ims[l_idx], interpolation='none')
subplot(122)
imshow(np.clip(f_im, 0, 1), interpolation='none')
<matplotlib.image.AxesImage at 0x16c64ebb0>
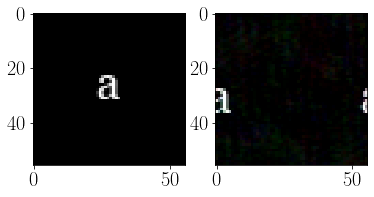
A toroidal image encoding#
There is a second special property to these vectors, which enables treating the image like a torus – as we translate to the right and move off of the right side of the image, we will end up on the left side. Same for top and bottom. For this to be possible, we design the base vectors by considering the identity vector and the roots of the identity vector.
What is the identity vector? Since the operation we are considering is element-wise multiply, the identity vector is simply a vector where each entry is 1.
When we apply the exponentiation trick to a root of the identity vector, then as we increase the exponent, we will eventually go in a loop. We choose the order of the root based on how long we want the loop to be. If we choose a square root of the identity, then we will loop every two steps. If we choose the 4th root, we will loop every 4 steps. Here, we chose a loop the size of the image – 56 pixels.
What are the roots of the identity vector? Of course, the square roots of 1 are (+1, -1). The 4th roots of 1 are (1, i, -1, -i). The N-th root of 1 are the \(N\) points around the complex plane: \(e^{2 \pi i k / N} \forall k = 1, ..., N\). Thus, to form a VSA vector that will loop when raised to the \(N\)-th power, we choose one of the \(N\) roots of identity randomly for each entry of the vector. This is implemented by the function \(\verb|cvecl|\).
loop_size = 10
loop_vec = ru.cvecl(N, loop_size)
pows = np.linspace(-15, 15, 200)
sims = np.zeros_like(pows)
for i, p in enumerate(pows):
sims[i] = np.real(np.dot(np.conj(loop_vec), loop_vec ** p)) / N
plot(pows, sims)
xlabel('Exponent')
ylabel('Similarity')
plt.tight_layout()
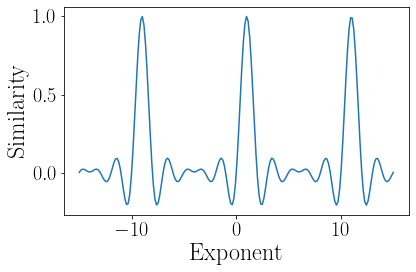
Here, we are examining the similarity between a loop vector and its powers. What we see is high similarity at power 1, as well as at powers 11, and -9. Because we designed the vector based on the roots, we can control how long it takes for it to loop!
Note here we are also exponentiating the vectors by fractional powers – we have the ability to perform fractional binding in the complex domain! This means that as we incremenet the exponent slightly we move smoothly along a manifold in the high-dimensional vector space.
loop_size = 1000
loop_vec = ru.cvecl(N, loop_size)
pows = np.linspace(-15, 15, 200)
sims = np.zeros_like(pows)
for i, p in enumerate(pows):
sims[i] = np.real(np.dot(np.conj(loop_vec), loop_vec ** p)) / N
plot(pows, sims)
# compare to the sinc function
plot(pows+1, np.sin(np.pi*pows)/(np.pi*pows))
xlabel('Exponent')
ylabel('Similarity')
plt.tight_layout()
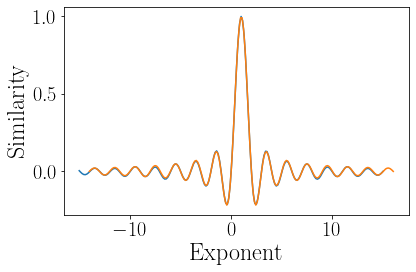
If we choose a very large loop size (or equivalently a completely random complex VSA vector), then we see a very special curve appear – the sinc function.
Dealing with correlations#
Now that we have a way to encode position (that is smooth and can loop), we next need to consider how to deal with encoding of shape and color.
The representation for the shape of the object will be linked closely to the representation of pixel location. In essence, the shape of the object is the set of pixel locations that are active. Thus the representation of a particular letter will be the sum of the vector encoding of each pixel location.
However, the issue that arises is that the shapes of the different objects are actually correlated. Conceptually, we want each letter to act as a symbol, meaning that it is orthogonal to the other letters. But the objects share many features in the pixel space. These correlations in the pixel space will cause issues with the resonator network when trying to solve the factorization problem. The solution to this issue is to use whitening on the patterns. Whitening orthogonalizes the patterns by adjusting the pixel magnitudes based on how many pixels are shared across letters.
def svd_whiten(X):
U, s, Vh = np.linalg.svd(X, full_matrices=False)
# U and Vt are the singular matrices, and s contains the singular values.
# Since the rows of both U and Vt are orthonormal vectors, then U * Vt
# will be white
X_white = np.dot(U, Vh)
return X_white
font_im_vecs = np.zeros((len(font_ims), np.prod(font_ims[0].shape[:2])))
for i in range(len(font_ims)):
font_im_vecs[i, :] = font_ims[i].mean(axis=2).ravel()
figure(figsize=(20,6))
for i in range(26):
subplot(3, 9, i+1)
imshow(font_im_vecs[i].reshape(font_ims[0].shape[:2]))
xticks([])
yticks([])

font_ims_w = svd_whiten(font_im_vecs.T).T
imshow(norm_range(font_ims_w[15].reshape(font_ims[0].shape[:2])))
<matplotlib.image.AxesImage at 0x175427910>
The whitened shapes look similar to the original shape with certain pixel emphasized or de-emphasized. We can see now that the shapes are orthogonalized.
original_xcorr = np.dot(font_im_vecs, font_im_vecs.T)
whiten_xcorr = np.dot(font_ims_w, font_ims_w.T)
figure(figsize=(8,4))
subplot(121)
imshow(original_xcorr)
xticks([])
yticks([])
subplot(122)
imshow(whiten_xcorr)
xticks([])
yticks([])
([], [])
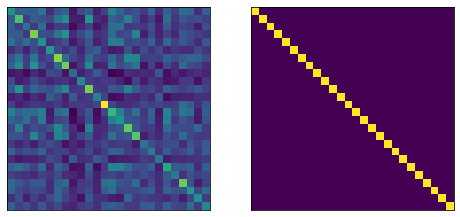
Now we will just encode the templates and the decorrelated templates into a vector. Note that we are not considering the colors and just using the pixel locations for the encoding.
font_vecs = ru.crvec(N, len(font_ims))
tst = time.time()
for i in range(len(font_ims)):
print(i, end=" ")
font_vecs[i,:] = encode_pix(font_ims[i].mean(axis=2), Vt, Ht)
print("elapsed:", time.time() - tst)
# this is stupidly slow, can be implemented by just a matrix multiply
# instead of a loop for better speed (need to store big matrix in memory though)
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 elapsed: 41.2913498878479
font_vecs_w = ru.crvec(N, len(font_ims))
tst = time.time()
for i in range(len(font_ims)):
print(i, end=" ")
font_vecs_w[i,:] = encode_pix(font_ims_w[i].reshape(font_ims[0].shape[:2]), Vt, Ht)
print("elapsed:", time.time() - tst)
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 elapsed: 41.22954177856445
In a similar fashion to the letters, we will also consider color as a factor. Further, we will use 7 different colors. But hmm… 7 colors can’t all be orthogonal because color is only a 3 dimensional space!
The whitening still has an effect, and is still necessary.
colors_dict = {'red': [1, 0, 0], 'green': [0, 1, 0], 'blue': [0, 0, 1], 'cyan': [0, 1, 1],
'magenta':[1,0,1], 'yellow': [1, 1, 0], 'white': [1, 1, 1]}
colors_arr = np.array(list(colors_dict.values()))
colors_lab = np.array(list(colors_dict.keys()))
cols_im = np.tile(colors_arr.reshape([1, colors_arr.shape[0], colors_arr.shape[1]]), [10, 1, 1])
imshow(cols_im*255, interpolation='none')
<matplotlib.image.AxesImage at 0x17550c400>

colors_svd = svd_whiten(colors_arr)
cols_svd_im = np.tile(colors_svd.reshape([1, colors_svd.shape[0], colors_svd.shape[1]]), [10, 1, 1])
imshow(norm_range(cols_svd_im), interpolation='none')
<matplotlib.image.AxesImage at 0x17556db80>

color_vecs = np.dot(colors_arr, Cv)
color_vecs_w = np.dot(colors_svd, Cv)
color_vecs_w.shape
(7, 30000)
Setting up the resonator network#
Now that we have VSA encodings that allow for translation and that deal with correlations in the templates, we can set-up the scene anlaysis problem as a factorization problem that can be solved by the resonator network.
The idea is that the scene is composed of several objects, and each object is composed from several factors – shape, color, horizontal and vertical location. We can store the atomic vectors for location and the decorrelated vectors for shape and color into the clean-up memories of a resonator network. When we present a scene (encoded into the VSA vector) to the resonator network, it will search through combinations of factors that best matches with the input scene.
res_xlabels = [colors_lab, np.array(list(letters)), np.arange(patch_size[0]), np.arange(patch_size[1])]
res_xticks = [np.arange(0, len(res_xlabels[0]), 3, dtype='int'),
np.arange(0, len(res_xlabels[1]), 8, dtype='int'),
np.arange(0, len(res_xlabels[2]), 10, dtype='int'),
np.arange(0, len(res_xlabels[3]), 10, dtype='int')]
# Here we are creating the clean-up memories for the resonator network
Vspan = font_ims[0].shape[0]
Hspan = font_ims[0].shape[1]
Vt_span = ru.crvec(N, Vspan)
Ht_span = ru.crvec(N, Hspan)
for i in range(Vspan):
ttV = i - Vspan//2
Vt_span[i,:] = Vt ** ttV
for i in range(Hspan):
ttH = i - Hspan//2
Ht_span[i,:] = Ht ** ttH
res_vecs = []
res_vecs.append(color_vecs_w)
res_vecs.append(font_vecs_w)
res_vecs.append(Vt_span)
res_vecs.append(Ht_span)
# Generate a scene of three objects with random factors
im_idx1 = np.random.randint(len(font_ims))
tH = patch_size[1] * np.random.rand(1)[0]
tV = patch_size[0] * np.random.rand(1)[0]
rC = np.random.randint(colors_arr.shape[0])
print(rC, colors_lab[rC])
t_im1 = font_ims[im_idx1].copy()
for i in range(t_im1.shape[2]):
t_im1[:,:,i] = colors_arr[rC, i] * t_im1[:,:,i]
t_im1 = shift(t_im1, (tV, tH, 0), mode='wrap', order=1)
######
im_idx2 = np.random.randint(len(font_ims))
tH2 = patch_size[1] * np.random.rand(1)[0]
tV2 = patch_size[0] * np.random.rand(1)[0]
rC2 = np.random.randint(colors_arr.shape[0])
print(rC2, colors_lab[rC2])
t_im2 = font_ims[im_idx2].copy()
for i in range(t_im2.shape[2]):
t_im2[:,:,i] = colors_arr[rC2, i] * t_im2[:,:,i]
t_im2 = shift(t_im2, (tV2, tH2, 0), mode='wrap', order=1)
######
im_idx3 = np.random.randint(len(font_ims))
tH3 = patch_size[1] * np.random.rand(1)[0]
tV3 = patch_size[0] * np.random.rand(1)[0]
rC3 = np.random.randint(colors_arr.shape[0])
print(rC3, colors_lab[rC3])
t_im3 = font_ims[im_idx3].copy()
for i in range(t_im2.shape[2]):
t_im3[:,:,i] = colors_arr[rC3, i] * t_im3[:,:,i]
t_im3 = shift(t_im3, (tV3, tH3, 0), mode='wrap', order=1)
#####
t_im = np.clip(t_im1 + t_im2 + t_im3, 0, 1)
figure(figsize=(3,3))
imshow(t_im, interpolation='none')
plt.tight_layout()
6 white
1 green
3 cyan
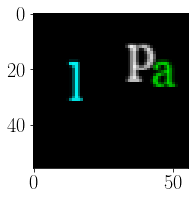
# encode the scene into a VSA vector
bound_vec = encode_pix_rgb(t_im, Vt, Ht, Cv)
# run the resonator dynamics
tst= time.time()
res_hist, nsteps = ru.res_decode_abs(bound_vec, res_vecs, 500)
print("elapsed", time.time()-tst)
converged: 82
elapsed 2.387779951095581
# visualize the convergence dynamics
figure(figsize=(8,3))
ru.resplot_im(res_hist, nsteps, labels=res_xlabels, ticks=res_xticks)
plt.tight_layout()
[6, 15, 19, 39]
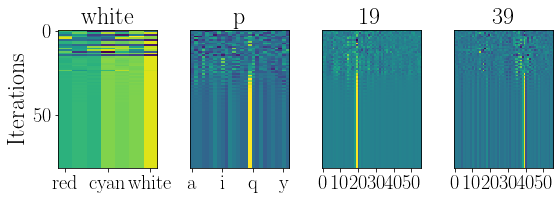
Here we see the resonator dynamics as it tries to find a solution. Each plot describes one of the 4 factors. The network will hone in on one particular object and find its factorization. The colors show the output of the network, with yellow indicating strong confidence on the output. The network will at first jump around the state space quite chaotically, until a good solution is stumbled upon and as if in a moment of insight the network rapdily converges to a factorization of the scene.
Explaining away to handle multiple objects#
The resonator network solves the factorization problem for one object at a time. In order to evaluate the rest of the scene, we expalin-away the output of the resonator network and reset the system. Now the resonator network will hone in and factorize a different object, and the process can be repeated for each object. This procedure is analogous to deflation in tensor decompositions.
out_w, out_c = ru.get_output_conv(res_hist, nsteps)
print(out_w, out_c)
[6, 15, 19, 39] 27
# When we explain away, we want to subtract out the original templates, not the whitened templates
res_out = color_vecs[out_w[0]] * font_vecs[out_w[1]] * res_vecs[2][out_w[2]] * res_vecs[3][out_w[3]]
res_out_sim = np.real(np.dot(np.conj(res_out)/norm(res_out), bound_vec/norm(bound_vec)))
print(res_out_sim)
0.7162521946027696
bound_vec2 = bound_vec/norm(bound_vec) - res_out_sim * res_out / norm(res_out)
tst= time.time()
res_hist2, nsteps2 = ru.res_decode_abs(bound_vec2, res_vecs, 200)
print("elapsed", time.time()-tst)
converged: 195
elapsed 5.388274908065796
figure(figsize=(8,3))
ru.resplot_im(res_hist2, nsteps2, labels=res_xlabels, ticks=res_xticks)
plt.tight_layout()
[3, 11, 25, 16]
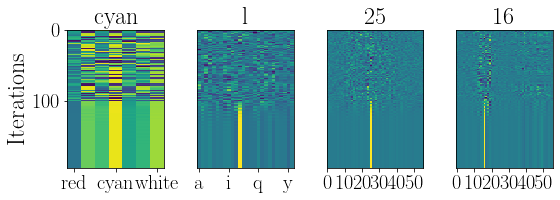
out_w2, out_c2 = ru.get_output_conv(res_hist2, nsteps2)
print(out_w2, out_c2)
[3, 11, 25, 16] 111
res_out2 = color_vecs[out_w2[0]] * font_vecs[out_w2[1]] * res_vecs[2][out_w2[2]] * res_vecs[3][out_w2[3]]
res_out_sim2 = np.real(np.dot(np.conj(res_out2)/norm(res_out2), bound_vec2/norm(bound_vec2)))
print(res_out_sim2)
0.7456184022083447
bound_vec3 = bound_vec2/norm(bound_vec2) - res_out_sim2 * res_out2 / norm(res_out2)
tst= time.time()
res_hist3, nsteps3 = ru.res_decode_abs(bound_vec3, res_vecs, 200)
print("elapsed", time.time()-tst)
elapsed 5.444526195526123
figure(figsize=(8,3))
ru.resplot_im(res_hist3, nsteps3, labels=res_xlabels, ticks=res_xticks)
plt.tight_layout()
[1, 0, 23, 47]